Celestia Deep Dives
Ethereum is being used in more and more scenarios today, leading to increased congestion and a growing gas fee, all of which are technical debts caused by flaws in the design of its native technical architecture. Ethereum's expansion is urgent, and the current EIP-4844 and a number of Rollups solutions are iterating to solve this problem. Still, none of them can escape one very important issue - data availability. There are many projects on the market that focus on DA issues, including Celestia and Avail, both of which try to use the DAS scheme to solve the DA problem by making the Light Client more powerful, and also those that use the Restake solution, including EigenLayer. Here I present to you Celestia, a project focused on DA layer solutions built on Cosmos SDK.
Celestia's technical features
Modular design
In a design similar to the current Ethereum, the blockchain is functionally coupled, and as we are constantly pursuing decoupling and abstraction in computer technology, we can also decouple the blockchain itself according to its function, and traditionally a complete blockchain would have four modules such as:
-
Data availability - Solving the problem of determining whether all the data in a new block has actually been published to the network.
-
Consensus - Bringing deals as well as sequencing to consensus
-
Settlement - Validation of certificates and settlement of disputes.
-
Execution - Confirming the validity of transactions and completing on-chain status updates.
We can increase the usability and reusability of components by modularizing different functions. For example, we can modularize the settlement layer by introducing fraud-proof or validity-proof, the settlement layer can increase the security of light clients by allowing them to verify the validity of blocks so that the liquidity present in the same settlement layer can be used by all the rollups on top. The DA layer is the foundation of all data processing in the blockchain, and we naturally want to decouple and abstract it through a modular design to provide a robust and reusable DA layer for the top infrastructure. The decoupling of the modules also gives each other more sovereignty, for example, we don't need to validate transactions packaged in the DA and we don't need to execute them, this is the sovereignty given to the different rollups on top of the DA layer.
2D Reed-Solomon Encoding
If you want to learn about the basics of Erasure Code, you can see this blog post at here.
Of course, this is only the most basic Erasure Code, if we use Fraud proof to prove the correct use of the Erasure code, an important factor to consider when designing the DA layer is the size of the fraud-proof. In a simple erasure code chunk, the entire original data block needs to be propagated to the light client in order to prove that the code is incorrect. The size of the fraud-proof is therefore at least proportional to the size of the block. To further reduce the size of the block then, we came up with the idea of using a high-dimensional Erasure Code scheme, 2D Reed-Solomon Encoding.
We do this by splitting the original data into k × k chunks arranged in a k × k matrix and expanding it with parity data into a 2k × 2k Reed-Solomon Encoding expansion matrix, so that there are 4k independent Merkle roots (calculated separately according to rows and columns), and these Merkle roots are the block data commitments in the block header.
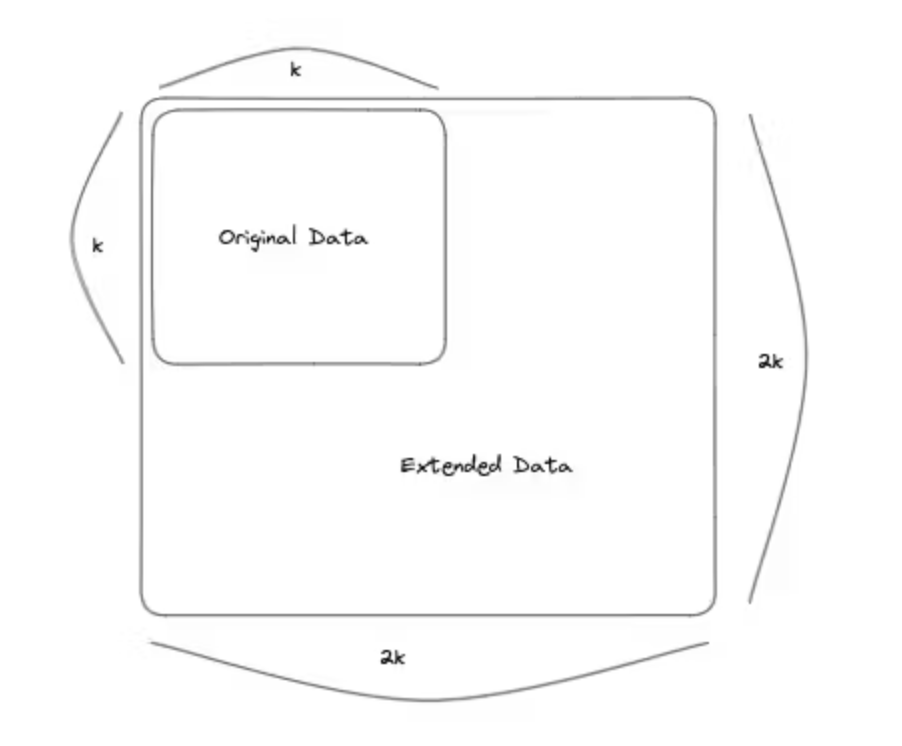
While a scheme based on high-dimensional erasure coding achieves a shorter fraud-proof size, it comes at the cost of a larger commitment, so this is a point where we need to make trade-offs.
Namespace Merkle Tree
This is a binary Merkle tree ordered by namespace, which causes any rollup on Celestia to download only the data associated with its chain, ignoring data from other rollups. Nodes in the tree are labeled by the minimum and maximum namespaces of their children, while their leaf nodes must be sorted in ascending namespace dictionary order.
NMT allows compact proofs to be provided around the inclusion or exclusion of shares with a particular namespace ID. (a share is a fixed-size chunk of data associated with a namespace whose data will be Erasure Code and committed to the namespace Merkle tree) The compactness promise can be calculated by obtaining a hash of the serialized root node.
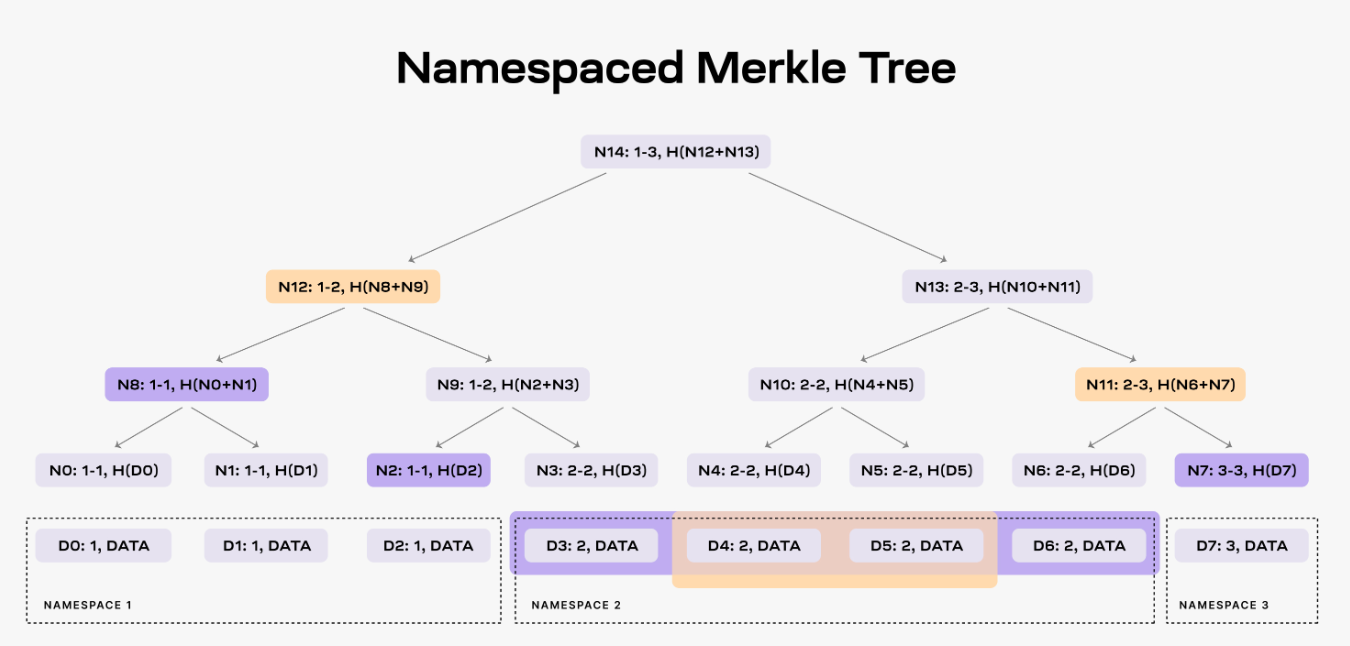
If we want to request data from Namespace 2, the DA layer will need to provide the data of the node N2, N7 and N8 in addition to D3-D6 to complete the proof. In addition, if we want to prove the validity of the data, we can also do so by using this structure. For example, if we need to verify the data in Namespace 2, if the DA layer provides chunks D4 and D5, then we also need to provide the node N11 and N12 to complete the final proof.
We can see that NMT splits the data according to different Namespaces. This structure is designed to meet the future isolation of the respective data by multiple Rollups without causing corresponding data contamination.
Celestia's architectural design
In Celestia there are two different networks with different functions and several different nodes and services to serve different application scenarios, currently, there are two networks in Celestia - the Consensus Network and the Data Availability Network.
Consensus Network
There are two types of nodes in Celestia's consensus network, the Validator Node and the Consensus Full Node, where the Validator Node is responsible for sorting transactions in blocks and reaching consensus in the network, and is the driving force in the consensus network. The Consensus Full Node, on the other hand, is responsible for synchronizing the history of the chain in the network.
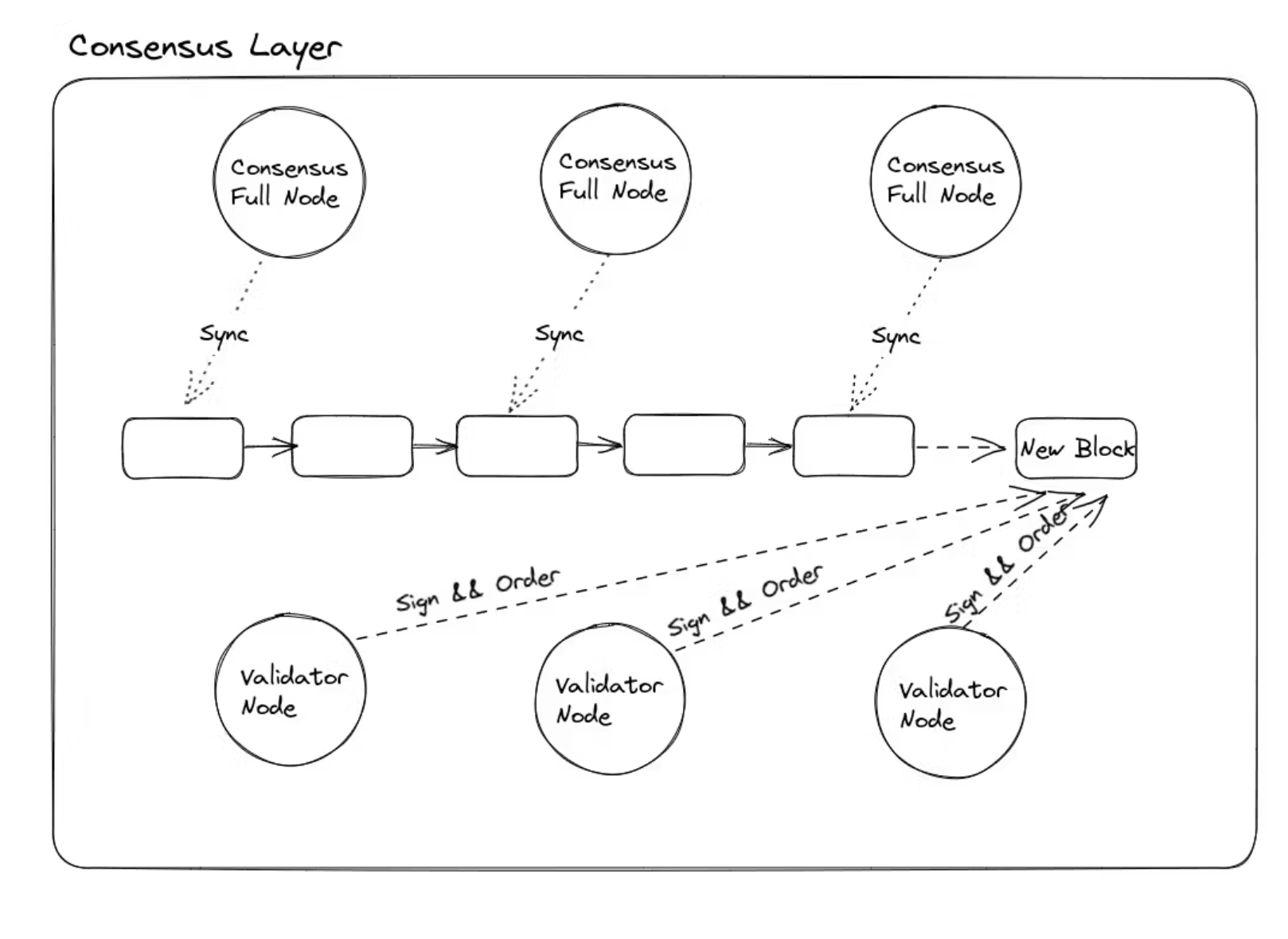
So both are based on the same design architecture as Celestia Core, but because of the need to complete signatures in the Validator Node, a Key Signer component is added to the implementation.
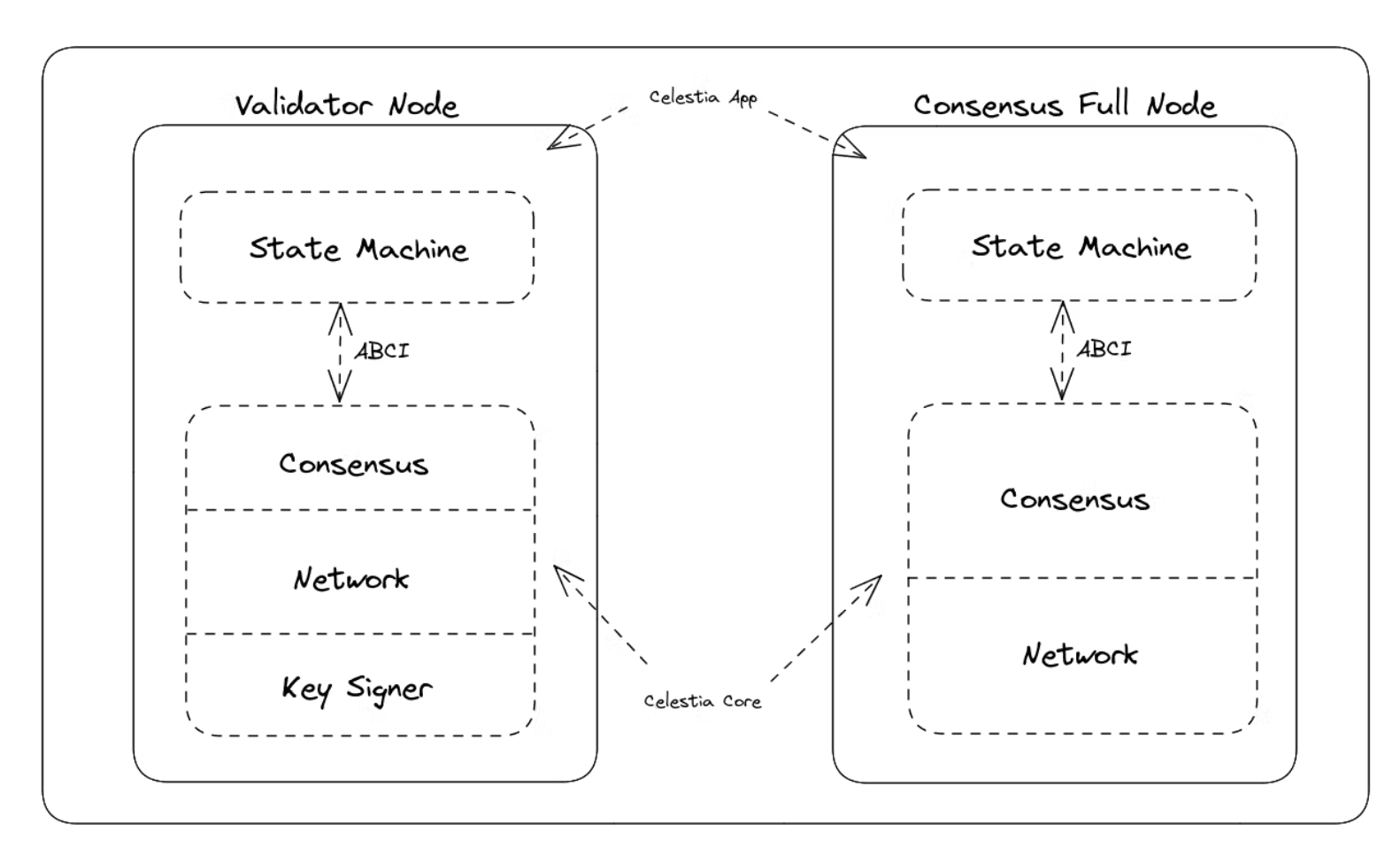
Celestia App and Celestia Core
Celestia-app is the state machine that runs the application and proof of stake logic. Celestia-app is built on the Cosmos SDK and it contains Celestia core. Celestia core is the state interaction, consensus, and block-generating layer. Celestia-core is developed based on Tendermint Core, where we will optimize the Merkle tree, using NMT as the storage structure.
Data Availability Network
The DA network is a special network split from the traditional blockchain, and we need nodes with special functions to achieve our design objectives, the most basic being a light node/light client to complete the DAS and a full node to help verify the security of the light node, in Celestia's case the Full Storage Node.
Full Storage Nodes store all the data in the network but are not connected to the consensus, while they can also send Block Shares, Headers, and corresponding Fraud Proofs to Light Clients, providing the security guarantees necessary for Light Clients, while at the same time sharing this information between Light Clients. Light Clients (LCs), as DAS-enabled light nodes, are the main actors in the Celestia network interaction, performing DAS on incoming headers and subsequently notifying Celestia nodes of new block headers and associated DA metadata.
Also due to the existence of two different networks, we need a bridging service, Bridge Node. The Bridge Node is a very important part of the Celestia DA network, as it connects the DA layer to the consensus layer, and we need to consider that the Bridge Node, as a bridge between two networks of different designs, needs to be able to accommodate both, but since the consensus network and the DA network have different functional requirements, they have been designed differently to minimize their functionality. The Bridge Node also needs to be able to adapt to both designs in its own implementation: it needs to be able to import header and blocks from the consensus network and perform related processing, i.e. validation and Erasure Code operations on the original blocks; and it also needs to be able to provide light clients in the DA network with Block shares with DA headers. The easiest way to achieve this adaptability is to implement both sides, so the Bridge Node architecture is shown in the following diagram:
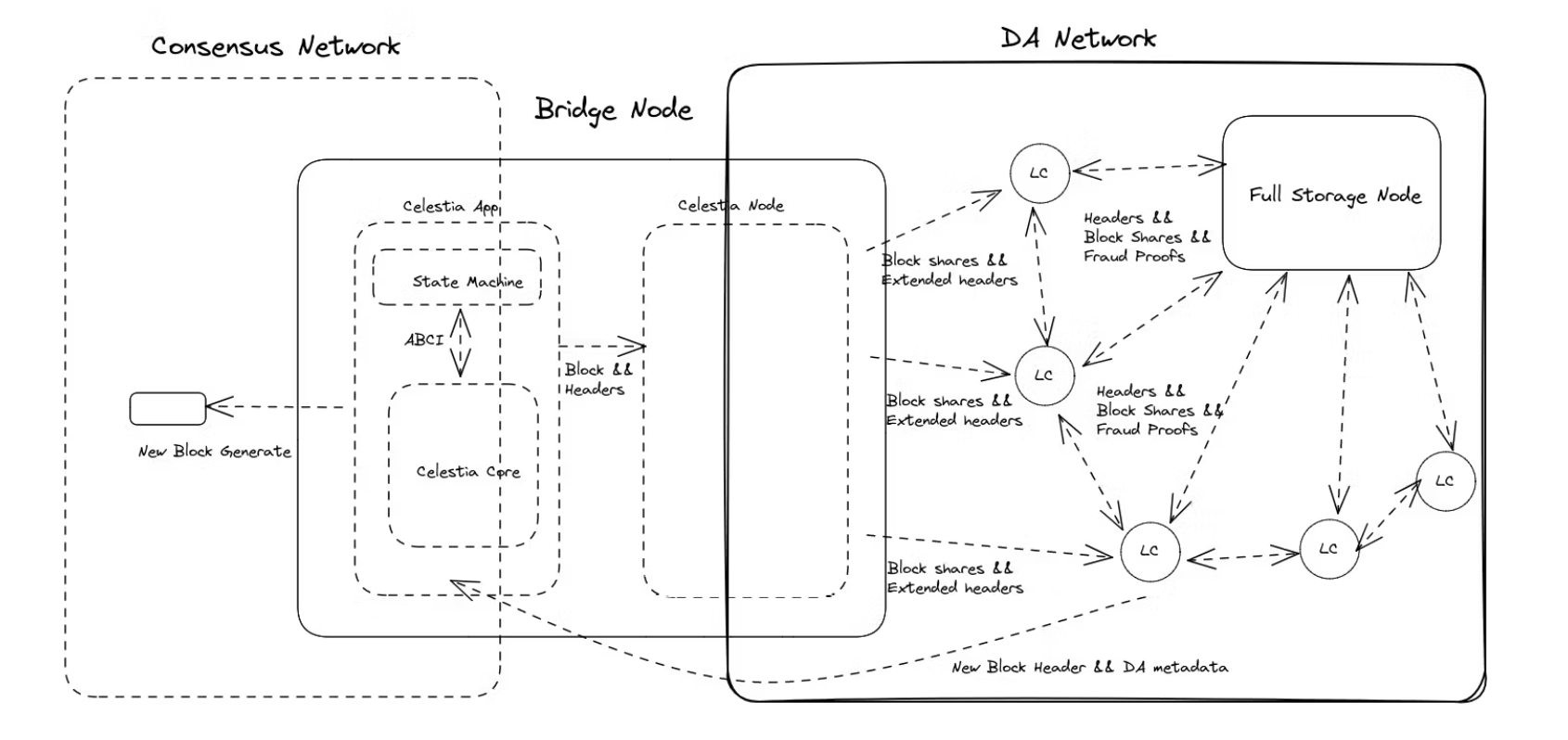
Celestia Node
The celestia-node is a service that uses a separate libp2p network in which the light nodes will perform their DAS.
Celestia's work flow
-
In Celestia, when we construct a transaction, we construct a structure like this:
type MsgPayForBlobs struct { Signer string Namespaces [][]byte BlobSizes []uint32 ShareCommitments [][]byte ShareVersions []uint32 } -
Before generating a block, we need to split such a structure:
-
Namespace structure (The namespace is an array of 29 bytes. The first byte is the version. The remaining 28 bytes are ids)
-
Executable transaction structure
-
-
The Block Producer adds the commitment of the block data to the Block header
-
Split the namespace and executable transaction again into multiple shares, where the shares will be prefixed with the namespace ID, thus associating the namespace with the executable transaction.
-
The shares are arranged in a square matrix
-
Extension with 2D-RS encode.
-
Calculate the commitment of each row and column of the extended matrix by NMT.
-
-
In this way, the commitment of the block data is the root of the Merkle tree, and its leaves are the roots of the forest of Namespaced Merkle subtrees, one for each row and column of the extension matrix.
-
Finally we will forward the new block header and associated DA metadata back to the consensus network via the bridge node, where consensus is reached and finality is completed.
Problems faced
Firstly Celestia, being a modular design focused on DA, does not perform any of the functions that need to be done at the execution level, and it therefore poses a number of problems:
-
How do you do a cold start? A DA layer network that does not do execution needs to rely on other execution chains to initiate user activity.
-
The utility of its token as a source of liquidity in DeFi and other verticals will be somewhat limited.
In addition to this, the size of the commitment (the root of the Merkle tree) is an important factor to consider in any design. With a large commitment, the blocks become larger, resulting in increased network traffic and increasing demands on the network bandwidth. And because Celestia's block size increases with the number of data sampling nodes in the network, and at the same time the data sampling process is not resistant to witch attacks (Sybil-resistant), there is no exact way to determine the true number of nodes in the network, the block size cannot be determined, and the throughput of the DA network is uncertain. A sybil attack could also cause a malicious consensus that could disrupt the entire network.
And there is also an incentive problem for sampling nodes. Currently, nodes involved in sampling are not directly rewarded, there is only an implicit incentive - they can gain more by maintaining the stability of the network, so how to design financial incentives regarding sampling nodes will also be a big issue in the future.
Outros
Celestia further extends the future of light clients by enhancing their ability to participate in the network with the help of DAS. It also provides a minimal application scenario for blockchains, i.e. a layer with only data availability, but which can be the basis of applications for other sovereign chains, providing them with effective shared security.
Sign up for our newsletter
Stay up to date with the roadmap progress, announcements and exclusive discounts feel free to sign up with your email.
© By Whisker —@whisker17